【C言語】整数型データ(short、int、long)を理解しよう!
前回の学習にて、ビット、バイトの概要は理解できたでしょうか。今回は、プログラムにおけるデータの型のうち、「整数型」と呼ばれるデータについて理解していきましょう。今回はプログラム書きますよー!
- 変数と四則演算の理解
- 整数型データ(short、int、long)の理解
- 「符号ビット」と「オーバーフロー」の理解
目次
変数
「変数」と「型宣言」
プログラムでは「変数」と呼ばれる、プログラム内で自由に数値を変えることが出来るデータを扱えます。
例えば以下のプログラムをそのまま張り付けて、動かしてみて下さい。(動かし方を忘れた方は、【第2回】「Hello World」を出力してみよう!に戻って復習してね!)
|
1 2 3 4 5 6 7 8 9 |
#include <stdio.h> int main(void) { int data = 5; printf("data = %d \n", data); return 0; } |
以下の様に出力されたと思います。
printf()の処理は、データの中身を表示しているだけと捉えて、現時点ではあまり気にしないでください。注目してほしいのは以下の記述です。
これは「変数宣言」と呼ばれる文になりまして、「型 変数名 = 初期値;」の形式で書くことが出来ます。今回で言うと、「int型の変数dataを5で初期化します」という文になります。
変数は初期化後も、任意のタイミングで値を書き換えることが出来ます。例えば以下のように書くと、「data」は100になります。
|
1 2 3 4 5 6 7 8 9 10 |
#include <stdio.h> int main(void) { int data = 5; data = 100; printf("data = %d \n", data); return 0; } |
変数は何個でも(正確にはプログラムメモリが許す限り)宣言することが出来ます。例えば以下の様に、たくさんのデータを初期化することも可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <stdio.h> int main(void) { int data1 = 1; int data2 = 2; int data3 = 3; int data4 = 4; int data5 = 5; printf("data1 = %d, data2 = %d, data3 = %d, data4 = %d, data5 = %d \n", data1, data2, data3, data4, data5); return 0; } |
四則演算
変数は、演算子「+」「-」「*」「/」を使って、加減乗除の演算が行えます。
以下のコードを張り付けてみて動かしてみて下さい。ちなみに1÷2は0.5ですが、変数「data」が整数型(int)ですので、答えは整数に丸められて、0になります。自分で色々いじってみて動かしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#include <stdio.h> int main(void) { int data = 0; data = 1 + 2; printf("1 + 2 = %d \n", data); data = 1 - 2; printf("1 - 2 = %d \n", data); data = 1 * 2; printf("1 * 2 = %d \n", data); data = 1 / 2; printf("1 / 2 = %d \n", data); return 0; } |
1 + 2 = 3
1 – 2 = -1
1 * 2 = 2
1 / 2 = 0
また、演算項には変数も使用することが出来ます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#include <stdio.h> int main(void) { int data = 0; int a = 5; int b = 3; data = a + b; printf("data = %d\n", data); return 0; } |
整数の型
整数の型「short」「int」「long」
それでは、数ある型のうち、整数を扱うものを見ていきましょう。
| 型名 | バイト数 | データ範囲 |
|---|---|---|
| short | 2 | (符号無し)0~65535 (符号付き)-32768 ~ 32767 |
| int | 2 or 4 | (符号無し)0~4294967295 (符号付き)-2147483648~2147483647 |
| long | 4 | (符号無し)0~4294967295 (符号付き)-2147483648~2147483647 |
| long long | 8 | (符号無し)0~18446744073709551615 (符号付き)-9223372036854775808 ~9223372036854775807 |
上表で扱う型が、一般的に整数として扱う型になります。
int型は少し特殊で、データサイズが2byteになるか4byteになるかはコンパイラに依存します。最近のPCを利用している方はほとんどが4byteになるので、ここではint = 4byteで説明していきます。
また、short、longは、正しくは「short int」、「long int」と、最後にintを付けるのですが、大抵のコンパイラは省略しても同じ意味で通りますので、省略します。
short、int、longの概念は、他の言語(Java、C#等)でもほぼほぼ同じとなります。
符号ビットと「signed」「unsigned」
ここで、「符号無し」「符号付き」について解説します。
例えばshortであれば、2byteデータになります。これは16bit分のデータになりますが、この先頭ビットを数値として扱うか、符号(+-)として扱うかを選択できます。
型宣言をそのまました場合、もしくは「signed」という修飾子を付けた場合は「符号付き」、「unsigned」という修飾子を付けた場合は「符号無し」になります。unsignedの場合のみ、先頭ビットが「符号」として扱われます。
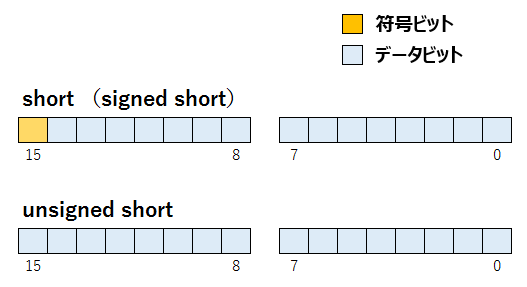
見てもらって分かる通り、「unsigned short」の場合は16ビット全てを数値として使用できるので、データの範囲は「0~0xffff(65535)」となるわけです。0xffff = 65535となる理由が分からない方は、前回の記事に戻ってみて下さい。
一方、「short」「signed short」の場合は15ビットを数値として使用しますので、データの絶対値の範囲は「0~0x7fff(32767)」となります。それに-が付くので、そのまま素直に考えると「-32767~32767」になりそうな気がしますが、実は2の補数という考えにもとづき、-側だけ範囲が1増えて、正しくは「-32768~32767」になります。
int、long longに関しても同じです。unsignedの場合はバイト数全てがデータ範囲になりますが、signedの場合は先頭ビットが符号扱いになり、-側だけ表現範囲が1大きくなります。
オーバーフロー
それでは、データ範囲を超えるような値を代入した場合、データはどうなってしまうのでしょうか。unsigned short型に「65535」を超えるような値を入れた例を考えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#include <stdio.h> int main(void) { unsigned short data = 65535; printf("data = %d\n", data); data = data + 1; printf("data = %d\n", data); return 0; } |
data = 65535
data = 0
実行してみたら分かる通り、65535の次は0に戻っていることが分かります。これは内部的には1ビットを加算する処理を行っており、「11111111 11111111」に1を足した結果、「00000000 00000000」に戻るという動きをしているからになります。これをオーバーフローと言います。プログラムの型のデータサイズを理解せずに発生させてしまう不具合となりますので、必ずデータサイズを意識して演算を行うようにしましょう。
まとめ
ここまでの内容は理解できたでしょうか。少し内容が多かったと思うのでここで1回切ります。ここまでの内容で良く分からない箇所は、前回の記事と合わせて復習してみて下さい。
次回は文字列を表現するのに相性のいい「char型」について解説していきます。お疲れ様でした。